Jeff Doyle on the Network Automation Framework: CHI-NOG 13
Declared bias up front. Jeff Doyle is a friend, but that doesn’t influence what comes next. If you’ve cracked open Routing TCP/IP Volume 1 or 2 in the last twenty-something years (and if you sat for the CCIE, you have) you’ve read his work. So when Jason introduced him as the CHI-NOG 13 keynote and Jeff opened by admitting this was his first CHI-NOG, that landed for me. Longtime NANOG denizen, occasional IETF attendee, and somehow the Chicago show had never made his calendar until this year. “Please be gentle with me,” he said, which is the kind of line only a guy who’s spoken to thousands of network engineers over thirty years gets to use without sounding precious.

He came to talk about the Network Automation Framework, which the Network Automation Forum has been refining out of the AutoCon conferences. Scott Robohn (co-founder, also a CHI-NOG 13 speaker) was in the room. Jeff pointed at him during the intro. “If there’s anything you don’t like about what I say today, I’ll point you to Scott.” Classic Doyle.
What follows is what he covered, what’s genuinely useful about the framework, and where most ops shops fall down when they try to apply it.
Why this framework exists
Doyle’s opening drivers were familiar to anyone who’s been in this game long enough. Network complexity has gotten past the point where node-by-node CLI management is sane. If you’ve got fifty boxes to touch for a single change, you’re either in some kind of half-broken state for the duration of the change window or you’ve already moved to automation.

That last bullet is the one that won’t go away. Doyle’s been pointing at human error as a leading cause of outages for the better part of two decades, and he put the 2025 Uptime Institute Annual Outage Analysis Report on the slide because it still bears that out. People fat-fingering commands. Failure to follow procedure. And the one that makes consultants wince, organizations that have no documented procedures at all. Jeff’s walked into surprisingly large companies, asked for the policies and procedures binder, and gotten a shrug. Automation, whatever else it does, forces you to write down what “right” looks like. That alone is worth something.
The other driver worth pulling out. Architects shouldn’t be firefighters. Jeff’s lived experience as a consultant, especially in medium-to-smaller networks, is that he asks architects about their one-year and three-year plans and gets some version of “we don’t really have any, most of our job is putting out fires.” If your architects are doing tier-three operations, nobody is doing the actual architecture, and the network you have five years from now is the one that emerges from accumulated tactical patches, not the one anybody designed.
The cultural-resistance angle, in 2026
Jeff walked through the barriers slide next. Automation is itself complex. NOS diversity makes the abstraction problem real. Poor definitions of what “automation” even means inside a given shop. Cultural resistance. Fear.

Cultural resistance is where I want to spend a minute. Doyle used his standard Boeing 777 analogy. On an average flight, the pilot manually flies the airplane for about seven minutes. The rest is automated. The pilot is still in the cockpit, still essential, but no longer distracted by minute-by-minute manual control inputs. The analogy maps cleanly onto network ops. Pull the operator out of node-by-node CLI work and let them see the whole network as one entity.
It’s a good analogy. He’s been using it for years. But it lands differently in 2026 than it did when he started giving the talk, and we have to be honest about that. The last few years of layoffs in networking and adjacent infrastructure have done a number on the room. When Jeff says “this doesn’t mean you don’t need a pilot,” every operator in the room has done the math on whether their company would agree. Some companies absolutely have used automation as cover for cutting headcount. Pretending otherwise is dishonest, and the people you’re trying to convince to embrace automation already know.
The better framing, and the one I think Jeff is really getting at, is that “keep all the operators” was never the alternative on offer. The real one is losing ground to the shops that automated, and then losing the operators anyway. Cultural resistance to automation in 2026 is rational. It’s just a worse bet than learning to drive the new tools and being one of the operators still here in 2030. Tell that story honestly and you might get buy-in. Trot out the pilot analogy without acknowledging the layoff context and the room sees right through it.
Approaches: DIY, COTS, open source, hybrid
Quick tour. DIY is OpEx-intensive but builds exactly what your network needs. COTS is CapEx-intensive, fast to deploy, and comes with bells and whistles you don’t want. Open source is the middle road, customizable with community support, but somebody still has to wire it together. Hybrid means combining all of them, building what you can, buying what you must, deploying gradually.
My take. For most operator shops I’ve seen, hybrid is the only realistic answer, and the smartest hybrids buy commercial for the boring well-understood parts (state collection, basic dashboards, ITSM integration) and build custom for the parts that actually express how your organization thinks about its network. The shops that try pure DIY underestimate the glue work and end up with a bespoke platform that one person understands and nobody else can maintain. The shops that try pure COTS spend six figures on a vendor platform and then write a hundred Python scripts around it to make it do what they actually wanted.
The framework itself
The centerpiece. Jeff’s slide stacks seven boxes bottom-up, but only six of them are functional layers. The box on the bottom is the infrastructure itself, the thing you’re actually touching: routers, switches, firewalls, DNS, load balancers, whatever qualifies as managed state. It’s the network everything else acts on. The six layers stacked above it are what the framework is really about.
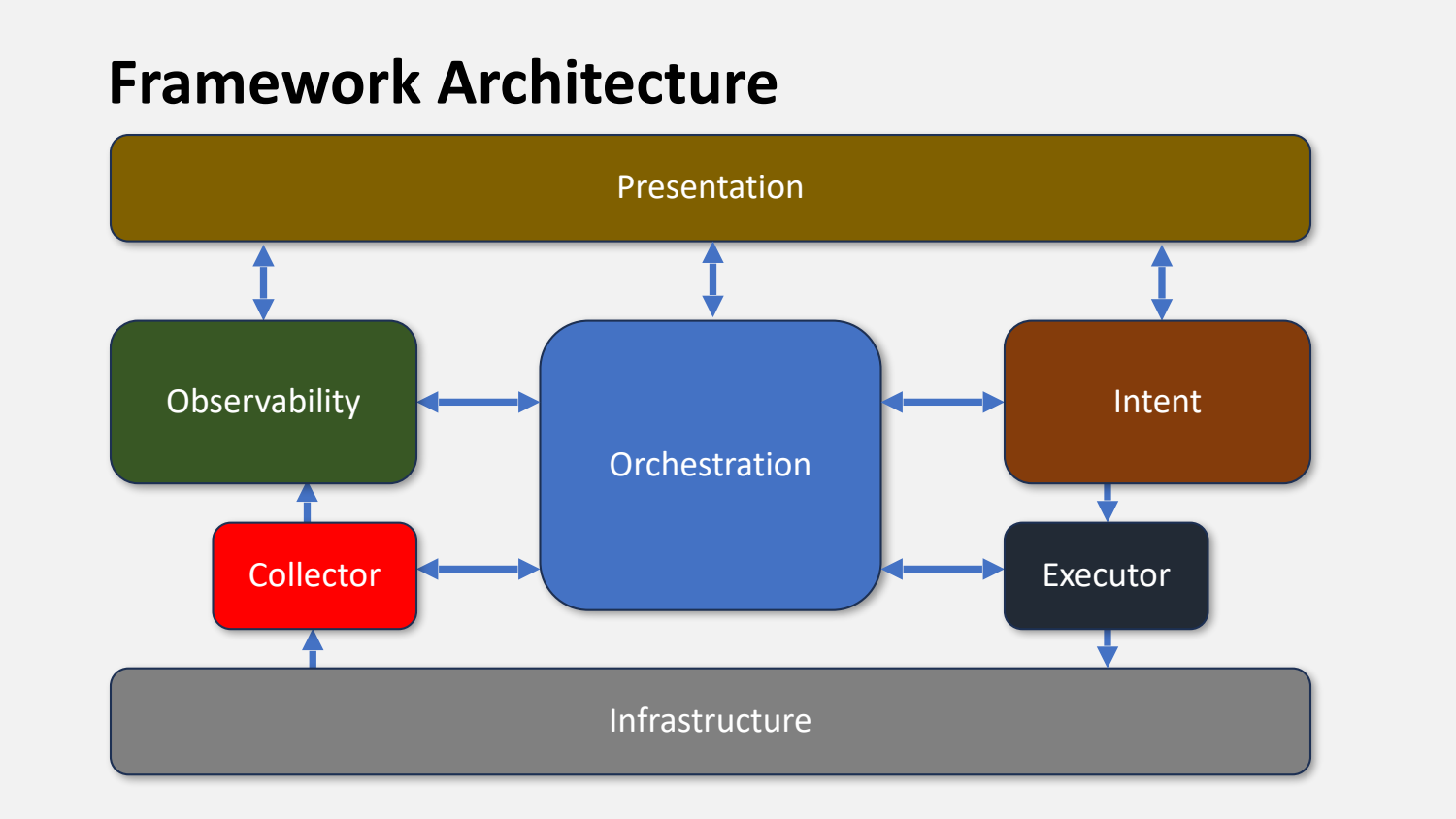
Quick brief on each, bottom up:
- Collectors read state from the infrastructure. SSH, gNMI, NETCONF, RESTCONF, SNMP if you’re still in that life.
- Observability is the database of what’s actually out there. Where collected state lives, gets normalized across vendors, and becomes queryable. Where Doyle anchored his single-source-of-truth point.
- Intent is the counterpart to observability. Observability says “this is what I have.” Intent says “this is what I want.” Expressed against an abstraction of the network, not against specific vendor configs.
- Executors write to the infrastructure. The opposite of collectors. They translate abstract intent into NOS-specific commands.
- Orchestration ties it all together into workflows. Scheduling, events, rollback, dry-run capability.
- Presentation is the user interface. Dashboards, GUIs, CLI tools, AI gateways. Not necessarily a single pane of glass, regardless of what your vendor tells you.
The whole thing is meant to be vendor-neutral and serve as an evaluation lens for any automation effort, DIY or COTS or anywhere in between. The evaluation-lens framing is the most useful part of it. You can take this diagram into a vendor demo and ask uncomfortable questions about what’s actually present and what’s hand-waved over.
Where I think most shops actually struggle
The framework as a checklist is fine, but it doesn’t tell you which layers are going to hurt. Here’s where I see the most pain, layer by layer.
Collectors and observability are usually OK. Most ops shops, even ones that haven’t done formal automation, have something collecting state. Telegraf into Prometheus, some flavor of NMS, gNMI streaming to a TSDB if they’re a bit further along. Grafana dashboards built up over years. Rarely elegant, almost never normalized across vendors, but the bones exist. When I review an existing automation effort, this layer is least likely to be the bottleneck.
Intent is where shops fall apart. Almost universally. Doyle’s point about poor definitions hits hardest here. You can’t express what you want if nobody’s written down what you want. I’ve sat in design reviews where the team had a beautiful executor pipeline ready to go and then couldn’t agree on what a “standard access switch configuration” was supposed to be, because three engineers had three different ideas and the documentation was eight versions behind. Intent is a writing problem before it’s a tooling problem, and most engineering orgs are bad at writing.
Executors are usually fine because they’re the easiest layer to buy. Ansible. Nornir. Vendor APIs. The mechanics of pushing config are a solved problem. The only time this gets ugly is when intent is malformed, because then your executor is faithfully deploying nonsense at machine speed.
Orchestration is where shops over-engineer. Everybody wants to build a workflow engine. Most shops don’t have the volume of distinct workflows to justify the abstraction. If you’ve got three things you automate, you don’t need Apache Airflow. You need three scripts and a cron job.
Presentation is where vendors slap on a UI and call it done. I’ve seen too many COTS platforms where 80% of the engineering effort went into the presentation layer because that’s what closes the deal in a demo. The dashboard is gorgeous. The CLI tool looks just like the device CLI. The intent and observability layers underneath, the actual hard problems, are anemic. Get sold on a presentation layer without auditing what’s underneath and you’ve bought yourself a beautiful empty box.
So if you’re applying the framework as an evaluation lens, spend the most time on intent (do they actually have a way for you to express what you want in a vendor-neutral abstraction, or are they just templating Jinja over Cisco IOS?) and on observability (can it normalize across NOS diversity, or does each vendor get a separate dashboard?). That’s where the gap between “we have a thing” and “we have the thing that solves the actual problem” is widest.
Single source of truth, and why bringing the term back matters
Doyle did something I appreciated. He used the phrase “single source of truth” without apology, and acknowledged it’s a term that’s fallen out of favor lately, replaced in vendor marketing by “model-driven” or “intent-based” or whatever the next abstraction noun ends up being. He still likes the original framing, and I’m with him.
“Model-driven” tells you about the implementation. “Intent-based” tells you about the interface. Neither tells you about the property we actually want, which is that there is one place where the answer to “what is the network supposed to look like” lives, and everything else derives from it. If your config generator, your monitoring system, and your change-management process each have their own slightly-different idea of what the network is supposed to be, you don’t have a single source of truth no matter how model-driven any of those individual systems are. Reintroducing the term is a small thing, but the original meaning is what the industry still hasn’t delivered on. Doyle’s right to keep pointing at it.
The part of the talk I’m still thinking about
Doyle ran past his question time. He’s notorious for it, by his own admission. In the Q&A he did get to, somebody asked about engineers and the storytelling problem. How often do you see engineers who don’t know how to talk about the problem to executives versus engineers who don’t know how to fix it?
Doyle’s answer was the most useful thing in the whole keynote.
His take: engineers like to talk in definites. We look at a network, we see numbers, we report those numbers with the same confidence we’d report TCP MSS. The business side talks in probabilities. There’s no guarantee, but there’s an 80% chance. Engineers stiffen up at that framing because we trained ourselves to be uncomfortable saying “I’m 95% sure” when we don’t have proof of 100%. So we either over-claim certainty we don’t have or refuse to commit to a number at all, and both failure modes torch our credibility with executives.
His book recommendation was How to Measure Anything by Douglas Hubbard. Not a book I’d have associated with network engineering at first glance, but it’s been on my own shelf for a while, and Doyle’s right that it’s one of the most useful things an engineer can read. The premise is that anything that matters is in principle measurable, and the path to measuring it is asking enough questions to break the unquantifiable thing into smaller quantifiable pieces. Hubbard’s calibration training (the chapters on getting yourself to honestly assess your own confidence intervals) is the missing skill for engineer-to-executive translation. You learn to say “I’m 80% sure this saves us $400K a year, here’s my reasoning, and here’s what I’d need to tighten the estimate” instead of either “I think it’ll save a lot” or “I can’t give you a number until we run a pilot.”
That probabilistic shift is the actual skill. Most of us in this room have been doing this work for decades and still cave to “I don’t want to commit until I’m certain” because the engineering culture trained us to. Read Hubbard. Get comfortable with calibrated estimates. It will do more for your automation business case than any framework slide deck.
Closing
The Network Automation Framework is one of the more useful pieces of vendor-neutral thinking that’s come out of the operator community in the last few years. Take it into your next vendor evaluation and use it as a checklist. Take it into your own DIY effort and use it to audit your own coverage. Either way it gives you a structure for the conversation that doesn’t depend on whoever’s pitching you this week.
The Boeing analogy needs a 2026 update for the layoff era, but the framework itself is solid, the single-source-of-truth resurrection is welcome, and the Hubbard recommendation should be required reading for anyone who’s ever had to justify infrastructure spend to a CFO. Jeff turns up at NANOG, the occasional IETF, and the AutoCon events, and he’ll talk to anyone who walks up. If you see his name on a schedule, go find him.
Watch the talk
CHI-NOG posted the recording. Watch Jeff lay out the framework in his own words.
Disclosure: Jeff Doyle is a friend, which I said up top and am saying again here. CHI-NOG didn’t comp my registration or travel. The Network Automation Forum didn’t buy me anything. Opinions are mine. For more, please read my full disclaimer.
Get the rest of CHI-NOG 13 in your inbox.