Networks Are Graphs. NetAI Acts Like It.
Dr. Deepak Kakadia got about ninety seconds into his NFD40 talk before he said the thing nobody else on the AI Ops circuit is willing to say out loud. LLMs were invented to model human behavior. Human behavior cannot really be modeled, which is why the models hallucinate. Networks, on the other hand, were built by humans, run on documented protocols, and have explicit structural relationships between every node and every edge. That’s a graph problem. Bolting an LLM onto your observability stack to do root cause analysis is using the wrong math, and the cost of that mismatch shows up as a confident-sounding “best guess” that hands the burden of asking the right question right back to the network engineer.
NetAI is the company built around the alternative bet. Co-founders Mike Hoffman (ex-Gigamon) and Dr. Deepak Kakadia (Sun Microsystems, Verizon Labs, Google, peer-reviewed papers, the works) are using graph neural networks to do root cause directly on the network’s actual topology, not on a vectorized text representation of it. They brought Irfan Lateef (sales engineering and BD) along for a real-time demo against a generic Tier-1 operator topology, and the demo did what most AI Ops demos don’t: it answered the followup questions instead of dodging them.
Why GNNs fit
Most “AI for networking” products today take alarms, syslog entries, traps, NetFlow, and config events, convert them into text or vectors, embed those vectors in a high-dimensional space, and use cosine similarity or dot product to find “close” matches. That’s two layers of indirection on data that already has explicit structure. The relationships between an OSPF adjacency on one router and a layer-two flap on its neighbor aren’t fuzzy. They’re spec’d in the IETF documents you’ve been reading for twenty years. A graph that captures the actual topology and protocol layers already knows those relationships. A statistical word-similarity model has to be trained on every permutation of every alarm pattern and still ends up guessing.

NetAI builds a multilayer graph from the network it’s monitoring: layer one through routing, with separate graph layers for L2 adjacency, L3 IP, OSPF, BGP, MPLS, VxLAN, GRE tunnels, and so on. They get there by ingesting SSH/CLI configs (the running config is the intent), then running SNMP, GNMI, traps, syslog, NetFlow, and IPFIX in real time on top. CDP/LLDP for the layer-two bits, IP MIB for layer three, OSPF MIB and routing MIBs for the routing layers. When a fault occurs, the engine takes the relevant subgraph (Irfan called it the blast radius), feeds it through the GNN, and returns the root cause with a causal chain and an evidence timeline.
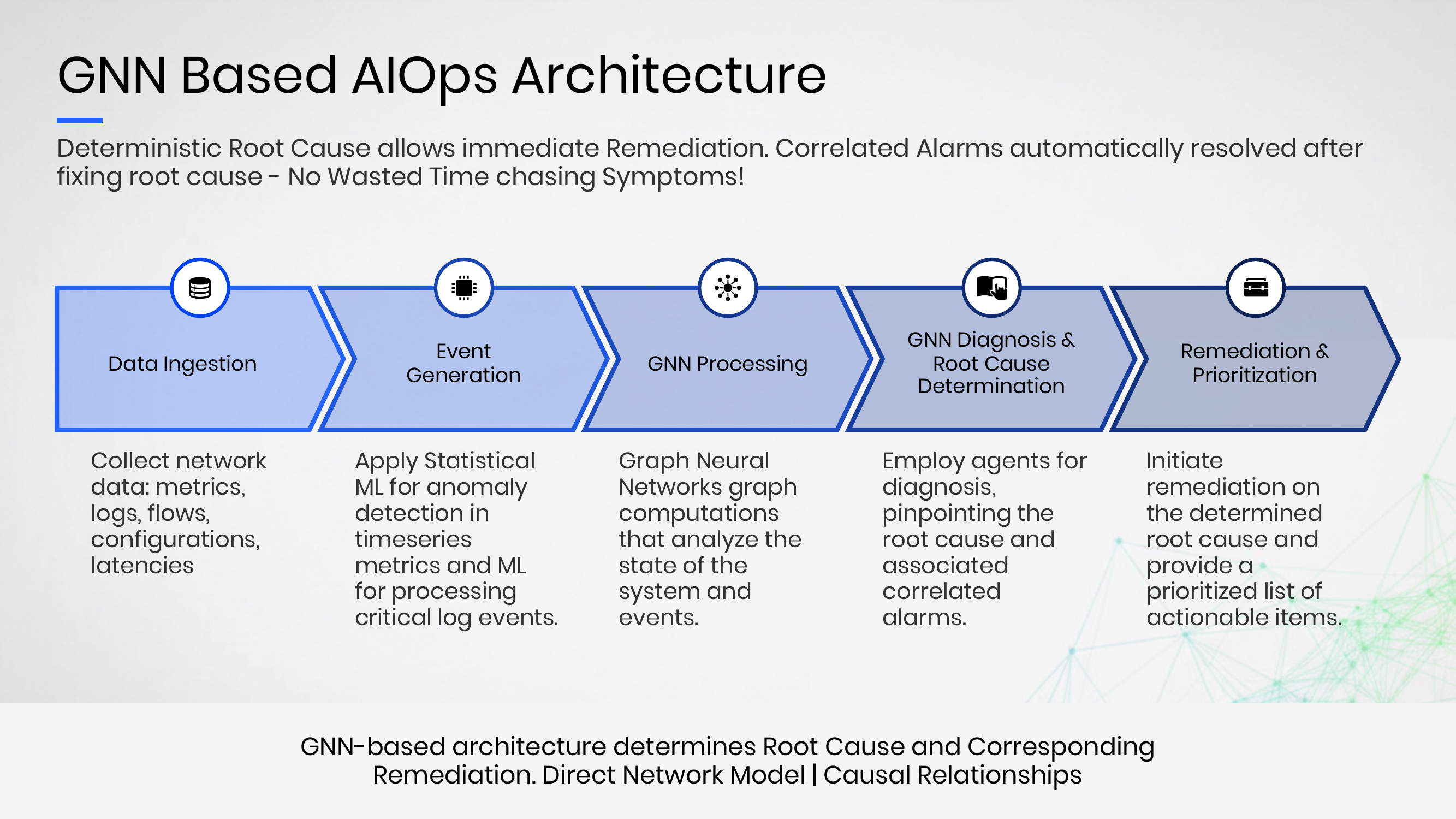
Deepak made one offhand comment that I’ve been chewing on since: “the digital twin is the GNN.” He’s right. The graph captures the state of the network at every timestamp it ingests, full topology plus configuration plus active state. If you’ve been wondering what a useful network digital twin looks like in production (rather than in a vendor slide), this is closer than most.

What “deterministic” means here
Deepak said the word deterministic roughly fifty times. Mike admitted up front that the lawyers and marketing wouldn’t let him claim 100% accuracy, but the framing both founders kept returning to was that they haven’t been proven wrong yet. That’s a strong claim, and the honest read on it is the part worth printing: NetAI’s root cause is deterministic given the data it’s been given. If the alarm fires, if the telemetry arrives, if the config gets pulled, the GNN will land on the same root cause every time, with the causal chain to back it up.
Garbage in, garbage out still applies. The realistic failure mode isn’t bad math, it’s missing data: the fiber cut that takes out the very link that would have reported the failure, the SNMP trap that got dropped, the device that nobody added to inventory. That’s where the answer got interesting. When the GNN expects a signal at a node and doesn’t see it, NetAI fires an agent that logs into the device and fetches what’s missing. The structural model already knows what the relationship between R1 and R2 is supposed to look like, so it knows what to go ask. That’s a real engineering answer to a real failure mode, and it’s the part most “deterministic” claims hand-wave past.
The other part worth flagging: “as long as it’s a known protocol.” Another delegate asked what happens when the system encounters something novel (the example floated was a new optic with one side dead), and Deepak’s answer was that anything running BGP, OSPF, IP, or any other documented protocol gets handled because the model captures how those protocols are supposed to behave. Anything truly unknown gets bubbled up via heuristic. That’s not a magic answer. It’s an honest one, and it’s the right tradeoff for a product whose job is to fix the 95% of incidents that look like the last 95% of incidents.
Closing the loop
The live demo did the thing the on-stage demo gods do not always reward. Irfan logged into a router on the demo topology, shut an interface, and let the alarms cascade. Twelve thousand alarms in the panel, twenty-five hundred classified as root causes, the rest correlated downstream. The GNN took roughly four minutes to converge on the actual root cause: configuration change at LAX1, Ethernet 0/1, blast radius traced from LAX1 to LAX2 to Charlotte to Chicago, full causal tree visualized at every protocol layer.

Then the auto-remediation kicked in. The agent ran a show run against the offending interface, confirmed the config showed the interface administratively down, and pushed the no shutdown to bring it back. The remediation scripts are user-supplied agent wrappers. The customer keeps full control over which fault classes auto-remediate and which open a ticket for human review. That’s the right answer. Nobody trusts AI to reboot a core router unattended. Most people will trust it to re-enable an interface a junior engineer accidentally shut, especially when the causal chain shows up in the ticket as evidence.
This is the part Google noticed publicly. Muninder Sambi, VP and GM of Networking at Google Cloud, wrote up the collaboration around MWC 2026, framing NetAI’s GraphML approach as the kind of specialized partner model that runs on Google’s AI stack and resolves incidents with enough confidence for autonomous action. Without the determinism, you can’t close the loop. With it, the loop closes itself most of the time.
Where the pitch stopped
A few things landed harder than the demo, because they were the bits where the company resisted the temptation to oversell.
“We only do networking.” When delegate Bruno Wallman asked about application-layer, storage, and database analysis, Deepak’s answer was clean: there are great companies doing that (he named resolve.ai), they integrate with them, NetAI stays in its lane. An honest scope statement in a market that punishes them.
“If there’s no alarm, we can’t do anything about it.” Asked about performance issues that don’t trigger anything, Mike answered honestly that those would fly under the radar unless their statistical layer happens to flag the time-series anomaly. Then they’d log in and look. No promise of telepathy.
The build-versus-buy market signal. Mike’s read on the customer base was the most useful sales-floor observation of the session. Service providers are nine to twelve months ahead of enterprises in this space because the SPs already tried to build this in-house, burned a year of engineering time, and gave up. The enterprise calls Mike takes still have thirty-seven software developers and zero network engineers on the line. They’re still in the build-it-ourselves phase. They will not be there much longer.
A note on delivery
Deepak’s stage presence is… a lot. “Get out of here. Just get it working.” “Ask my dad, maybe he knows.” “If it can bleed, you can kill it.” Pointed swipes at unnamed competitors as guys who “came out of county jail” yapping about AI. Some of it lands. Some of it doesn’t. The technical argument is strong enough that the personality is a sidebar, not the headline. If anything, the chaotic delivery is the tell that he genuinely believes the architecture is correct and is frustrated that the rest of the AI Ops market is taking the lazy path. I’ll take that energy over a polished pitch deck any day.
Worth your time
Most of the AI-in-networking space right now is variations on “we wired an LLM into our existing controller.” NetAI is one of the few sessions I’ve seen this year willing to argue for a different architectural starting point. The diagnostic (“LLMs are wrong for networking because networks already have explicit structure that LLMs don’t use”) is the kind of argument worth making, and the implementation behind it is far enough along that Google noticed and MasOrange ran a POC.
The product hits AWS Marketplace this week as NetAI Core (a flat $4,995/year non-AI version with a device cap, the same platform without the GNN engine attached) with the full GNN-enabled tier priced per element count.
Two-server minimum for on-prem (one big CPU box, one H100 GPU box). Cloud and hybrid deployment options too. If you’re already GCP-native, the whole stack (core platform plus GPU engine) can sit in your tenant with your network reaching in over a firewall. If you want the core on-prem but don’t want to wait three months for an H100, you can keep the core local and ship only normalized GNN math (no device identifiers, just the computation) to a cloud-hosted GPU. Two hours from deploy to productive, per Mike. I haven’t tested that claim, so take it as the vendor’s number, but the architecture supports it.

If you’re still trying to build your own correlation engine, this session is the one that should make you reconsider.
Disclosure: I attended Networking Field Day 40 as a delegate. My travel and accommodations were covered, but I was not compensated for this post and the opinions are my own. For more, please read my full Tech Field Day disclaimer.
Links & Resources
- Networking Field Day 40
- NetAI at NFD40
- NetAI
- Autonomous networks at MWC 2026 — Muninder Sambi, Google Cloud blog
Other Delegate Posts
- NFD40: NetAI Deterministic Analysis Enables Automated Problem Resolution - Peter Welcher, LinkedIn
- Networks Are Graphs, Not Language Problems: A Look at NetAI’s GNN Approach - Phil Gervasi, Solutional
- AIOps Fatigue Is Real, And It’s Your Vendor’s Fault, Not Yours - Ben Story, Pack It Forwarding
- Moving Beyond LLMs with NetAI and Graph Neural Networks - Tom Hollingsworth, Techstrong
Get the rest of Networking Field Day 40 in your inbox.