Nokia at NFD40: Networking in the AI Era
I’ve been building networks for nearly thirty years. I understand leaf-spine fabrics, BGP design, VRF isolation, ECMP, and congestion management. I’ve designed data centers for financial institutions where microseconds mattered and ISP backbones where five nines was the floor. None of that prepared me for the port math inside an AI data center.
Nokia brought five speakers to Networking Field Day 40 covering their AI networking portfolio: Patrick McCabe on the new network domains, Vivek Venugopal on Nokia Validated Designs, Alfred Nothaft on Ethernet’s evolution for AI, Zeno Dhaene on their EDA automation platform, and Igor Giangrossi on the hardware. The technologies were familiar. The scale was not.
The Port Math That Got Me
Nokia’s reference NVD uses two stripes of eight leafs each behind two spines, accommodating roughly 2,048 GPUs. That’s a solid lab validation target and a reasonable small cluster. It is also, by current industry standards, tiny.
xAI’s Colossus facility in Memphis hit 200,000 operational GPUs in 2025, with 555,000 purchased and plans for over a million. Meta ended 2025 with 1.3 million GPUs deployed across its fleet and is building Prometheus, a single 500,000-GPU cluster in Ohio drawing over a gigawatt of power. Meta’s Hyperion campus in Louisiana is designed for 5 GW. These are the clusters that frontier models are being trained on today.
Now do the port math at those numbers. In Nokia’s validated design, a single 8-GPU server consumes eight backend leaf ports (one per GPU NIC at 400G each), plus two more NICs for frontend and storage connectivity, typically dual-homed via ESI-LAG into a collapsed frontend/storage fabric. That’s ten physical switch connections per server before you’ve plugged in a management cable.
At 2,048 GPUs, that’s 256 servers and 2,560 server-facing ports. Manageable. Now scale it. A 100,000-GPU cluster is 12,500 servers and 125,000 server-facing ports, all needing non-blocking paths through a multi-tier fabric. At 100,000 GPUs with 400G per backend port, the aggregate southbound bandwidth on the backend fabric alone is 40 Pbps. Every one of those paths has to be non-oversubscribed, because when an all-reduce collective fires and every GPU in the cluster exchanges gradient data simultaneously, there is no room for congestion without direct impact on job completion time.
I’ve spent my career sizing uplinks with comfortable oversubscription ratios and calling it good design. In this world, oversubscription results in wasted GPU-hours, and GPU time bills by the hour.
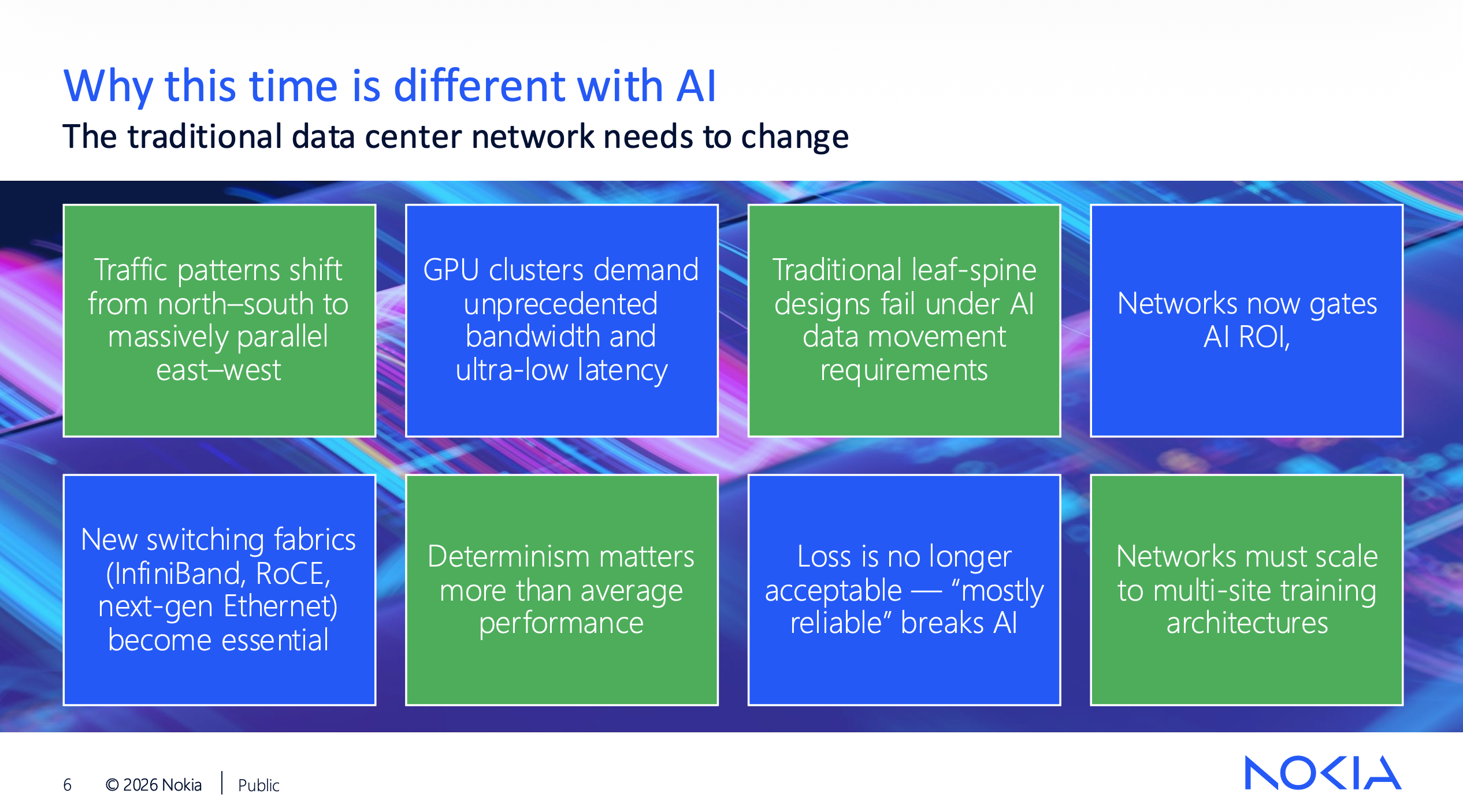
Three Separate Networks Per Cluster
Patrick McCabe’s presentation broke the AI backend into three network domains, each a separate design problem. Scale-up is GPU-to-GPU within a system, inches to meters, copper today with Ethernet moving in. Scale-out is system-to-system over Ethernet at 2m to 300m using backend switches. Scale-across is data center to data center at 10km to 1000km using DCI with coherent optics and deep-buffer routers.

Scale-across is often driven by power constraints. McCabe explained during Q&A that when you can’t source enough electrical capacity at one site, you split the GPU cluster across two locations and they still have to operate as a single compute entity. Meta is doing exactly this with multi-site clusters connected by ultra-high-bandwidth networks on a shared backend fabric. Igor Giangrossi added that managing scale-across performance starts in the GPU communication libraries, not just the network. The hosts understand the cluster topology and treat inter-site flows differently. It’s end-to-end tuning across every layer of the stack.
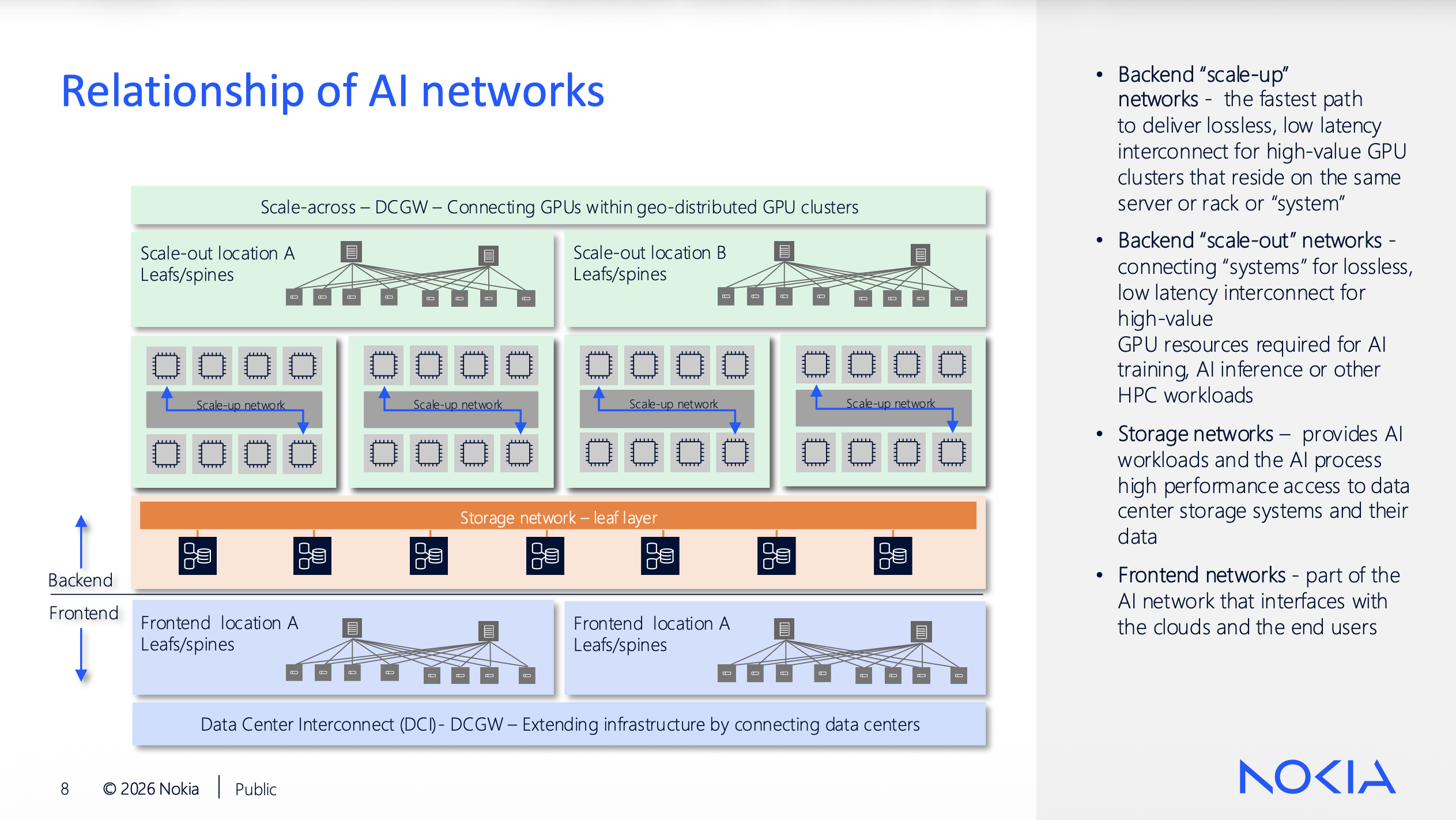
Nokia Validated Designs: Tested, Not Theoretical
Vivek V’s session on Nokia Validated Designs (NVDs) is where Nokia’s approach gets specific. These are prescriptive designs pinned to exact hardware (7220 IXR-H4, H5, D5 families), exact SR Linux versions, and exact configurations tested with real GPU workloads on physical gear.
The backend uses eBGP over IPv6 link-local addressing with VRF-based rail isolation: eight VRFs across the leaf switches, one per rail, GPU NICs mapped to the corresponding VRFs. The collapsed frontend/storage fabric runs EVPN/VXLAN with a single eBGP session carrying both IP and EVPN address families. Vivek mentioned during the session that future NVDs will move to /64 addressing with RA-based autoconfiguration for GPU endpoints, eliminating manual IP planning for the AI fabric. Given the interface counts at production scale, that’s not a nice-to-have.
Nokia publishes NCCL benchmark results for each NVD (all-to-all, broadcast, reduce-scatter, all-reduce across 8 to 32 GPUs), plus RoCEv2 perftest numbers and ML Commons training/inference benchmarks. Every NVD ships with a containerlab digital twin on GitHub that you can deploy without licenses or a sales call. Nokia treats NVDs like a product: regression-tested on every release, revised at least annually, supported for four years.
EDA: 100,000 Lines of Config From One Object
Zeno Dhaene’s live demo showed why automation at this scale isn’t optional. He deployed that full 16-leaf, 2-spine backend from a single EDA resource using label-based abstractions: nodes tagged by role and DC ID, interfaces tagged by tenant. No interface names, no per-device config. EDA resolved it into 2,115 output resources covering routers, interfaces, BGP peers, VRFs, and QoS parameters. At 2,048 GPUs that’s already over 100,000 lines of generated configuration. Scale that to a 100K-GPU deployment and you’re well past what any human can manage by hand.
Zeno framed the customer landscape as DIY (hyperscalers building their own stacks), DSY (teams mixing open-source and vendor tooling), and DNY (turnkey). NeoClouds typically start with Nokia’s shipped abstractions, then progressively build their own EDA intents to lock down parameters. EDA can pull source-of-truth data from Netbox or in-house systems. The whole platform runs on a laptop with simulated hardware. Try it at eda.dev.
The Hardware Stack
Igor Giangrossi covered platforms spanning Tomahawk 5 and 6 for scale-out (the 7220 IXR-H5 and H6 families, up to 128x800GE or 64x1.6TE) and Jericho 3 for scale-across (the 7250 IXR-X4 and the IXR-6e/10e/18e chassis family). The 18e chassis maxes out at 576 ports of 800GE across 16 linecards. Nokia claims 30% lower power per GE than competitors through a retimer-less single-PCB linecard design, midplane-less orthogonal cross-connect, and honeycomb mesh faceplates with 90% open area.
Igor confirmed that UEC features are landing incrementally by chipset: packet trimming on Tomahawk 5 today, credit-based flow control on Tomahawk 6. Nokia enables them in SR Linux as Broadcom adds them to the pipeline.
The Takeaway
The individual technologies here (BGP, EVPN/VXLAN, ECN/PFC, ECMP, VRF isolation) are things I’ve worked with for years. What hit me is the density at which they’re deployed and the zero tolerance for compromises I’ve always considered acceptable. One dedicated interface per GPU, non-blocking fabrics at every tier, lossless transport requirements, and clusters heading toward hundreds of thousands of GPUs. Nokia’s 2,048-GPU reference design is the building block, not the destination. Their combination of validated designs, EDA automation, and purpose-built hardware across scale-out and scale-across gives them a credible answer to a problem that is growing faster than most of us realize.
I’ve got some reading to do on those NVDs.
Disclosure: I attended Networking Field Day 40 as a delegate. My travel and accommodations were covered, but I was not compensated for this post and the opinions are my own. For more, please read my full Tech Field Day disclaimer.
Links & Resources
- Networking Field Day 40
- Nokia’s NFD40 Session Videos
- Nokia Validated Designs (NVD) Hub
- Nokia Validated Designs on GitHub
- Event-Driven Automation (EDA)
Other Delegate Posts
- Try Before You Buy: Nokia Is Taking Validated Designs Seriously - Ben Story, Pack It Forwarding
- NFD40 – Nokia Networking & AI - Peter Welcher, LinkedIn
- Powering Scale-Across Networking with Nokia - Tom Hollingsworth, Techstrong
- The Value of Validation with Nokia - Tom Hollingsworth, Techstrong
- NFD40: Scale-Across, Vendor Gravity, and the Elephant out of the Room - Scott Robohn, LinkedIn
Get the rest of Networking Field Day 40 in your inbox.